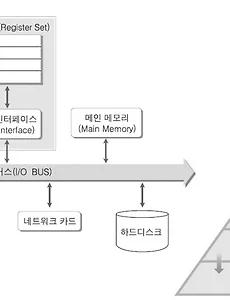
DFS를 이용한 스도쿠 문제 풀이 알고리즘
#include using namespace std; int sdocu[9][9]={0}; // 정답을 저장할 배열 int success = 0; // 성공변수 int dfs(int c, int r) { if(c==9) // 끝에 도달시 { success = 1; return 0; } if(sdocu[c][r]!=0) // 숫자가 있다면 { if(r==8) { c++; r=0; } else { r++; } dfs(c, r); if(success==1) { return 0; } if(r==0) // 되돌아가기 { c--; r=8; } else { r--; } return 0; } else { int temparr[9]={1,2,3,4,5,6,7,8,9}; // 빈칸에 들어갈 수 있는 숫자배열 for(int..
2010. 2. 5.